- One Cerebral
- Posts
- Stealing Weights from ChatGPT
Stealing Weights from ChatGPT
Research Scientist at Google Deepmind: Nicholas Carlini
Jiten Patel
January 15, 2025

Credit and Thanks:
Based on insights from The TWIML AI Podcast with
Sam Charrington.
Today’s Podcast Host: Sam Charrington
Title
Stealing Weights of a Production LLM Like OpenAI’s ChatGPT
Guest
Nicholas Carlini
Guest Credentials
Nicholas Carlini is a research scientist at Google DeepMind, specializing in the intersection of machine learning and computer security. He received his Ph.D. from UC Berkeley in 2018 and has since made significant contributions to the field of adversarial machine learning, earning multiple best paper awards at prestigious conferences like IEEE S&P, USENIX Security, and ICML. Carlini's work has been widely recognized, with coverage in major publications such as the New York Times, BBC, and Nature Magazine.
Podcast Duration
1:03:00
This Newsletter Read Time
Approx. 5 mins
Brief Summary
In a recent episode of the TWIML AI Podcast, Nicholas Carlini, a research scientist at Google DeepMind, discusses the evolving landscape of security in machine learning, particularly focusing on model stealing and data extraction techniques. He reflects on the significant advancements in large language models and the implications of these developments for both security researchers and practitioners. The conversation highlights the balance between innovation in AI and the pressing need for robust security measures to protect sensitive data.
Deep Dive
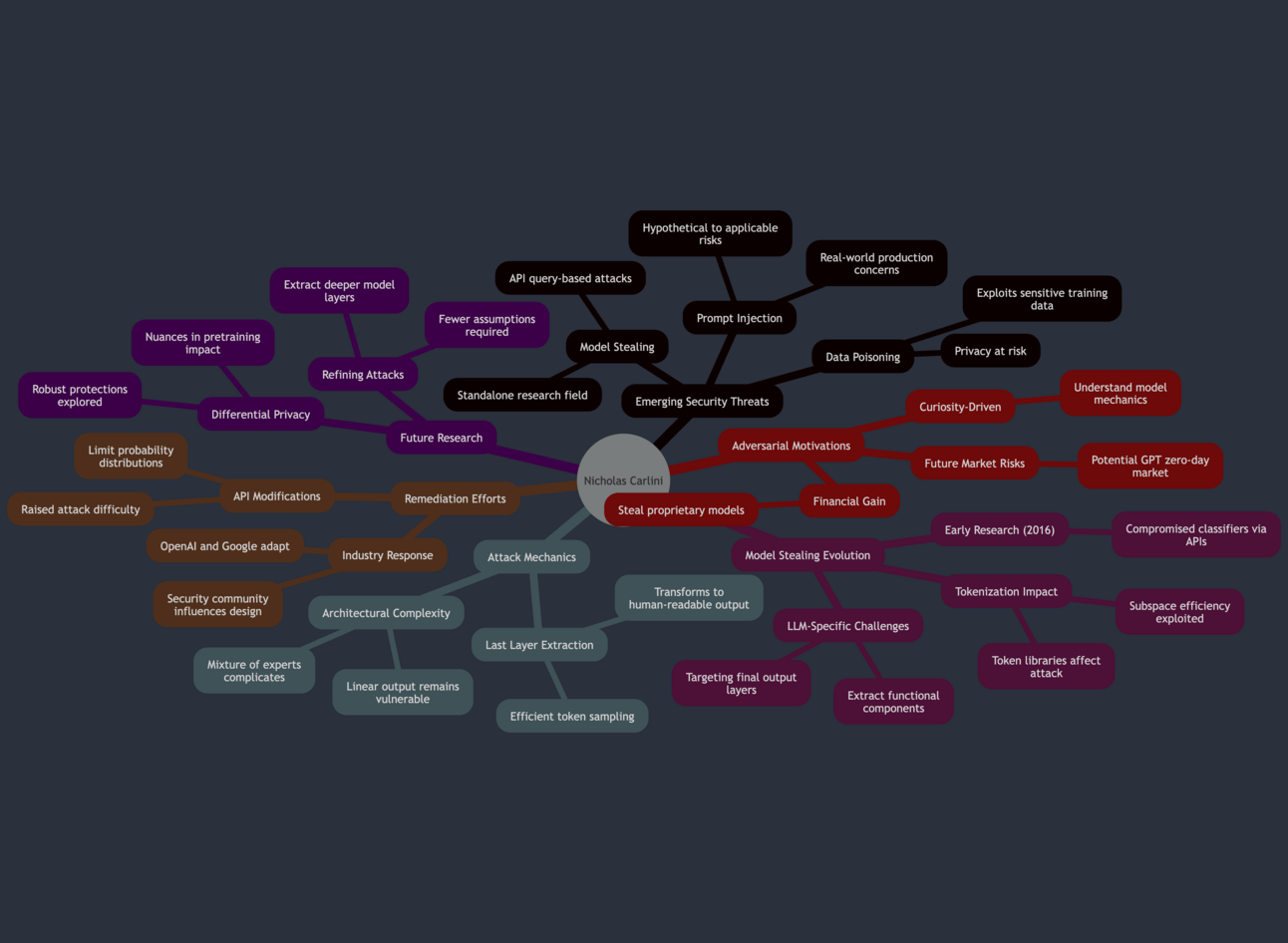
Carlini provides a comprehensive overview of the evolution of large language models (LLMs) and the emerging field of model stealing, which has gained traction as these models have become integral to various applications. Since the launch of ChatGPT, the landscape of machine learning has transformed dramatically, with researchers now focusing on real-world applications of security threats rather than hypothetical scenarios. Carlini notes that while the fundamental concerns—such as prompt injection and data poisoning—remain unchanged, the urgency and applicability of these issues have escalated as organizations deploy LLMs in production environments.
Model stealing has evolved into a standalone field of research, with its roots tracing back to early work in 2016 that demonstrated how simple classifiers could be compromised through API queries. Carlini highlights that the recent surge in interest is largely due to the proliferation of LLMs, which allow attackers to make queries to models without knowing their internal structures. This shift has prompted researchers to revisit and refine earlier techniques, leading to the development of new methodologies for extracting parts of these complex models.
In discussing the differences between his previous work on extracting training data from LLMs and his latest paper on stealing parts of a production language model, Carlini emphasizes that while both involve theft, they target different aspects. The former focuses on privacy concerns, where the aim is to recover sensitive training data, potentially harming individuals whose data was used. In contrast, the latter seeks to extract functional components of the model itself, which can undermine the financial and intellectual investments made by organizations in developing these models.
The mechanics of the attack on production language models are particularly fascinating. Carlini explains that the attack is designed to recover the last layer of a model, which is crucial for transforming internal representations into human-readable outputs. This process involves making numerous queries to the model, where the attacker collects probability distributions over various tokens. The nonlinearity inherent in the model's architecture allows for a more efficient sampling of the output space, as the outputs do not uniformly occupy the high-dimensional space but rather lie within a lower-dimensional subspace. This characteristic means that even with a limited number of queries, an attacker can effectively cover the necessary ground to extract valuable information.
Carlini also touches on the tokenization scheme used in LLMs, noting that while many models provide access to their tokenization libraries, the specifics of how tokens are generated and utilized can significantly impact the effectiveness of an attack. The discussion extends to the emerging architectures like mixture of experts, which complicate the landscape further. Carlini asserts that the attack methodology remains applicable as long as the final output projection is a linear transformation, regardless of the internal complexities of the model.
A significant aspect of the conversation revolves around the remediation approaches taken by organizations like OpenAI and Google in response to these vulnerabilities. Carlini expresses satisfaction that his research has prompted changes in API functionality, indicating that the security community's work is beginning to influence the practices of those who design and deploy these models. For instance, OpenAI modified its API to limit the ability to extract full probability distributions, thereby increasing the difficulty of executing the attack.
The motivations behind adversarial attacks are multifaceted. While some attackers may seek to steal proprietary models for financial gain, others might be driven by curiosity or the desire to understand the inner workings of these complex systems. Carlini speculates on the potential for a "GPT zero-day market," where vulnerabilities in LLMs could be traded, although he notes that the current economic incentives for such activities are still developing.
Looking ahead, Carlini outlines future directions for research in this area, including efforts to refine attacks that require fewer assumptions and exploring the possibility of extracting additional layers from models. He emphasizes the importance of approaching the problem from multiple angles to uncover new vulnerabilities and improve defenses.
In a related discussion, Carlini presents considerations for differentially private learning with large-scale public pretraining. He argues that while differential privacy offers robust protections against data extraction, the nuances of how models are trained and fine-tuned can lead to unintended privacy violations. For example, a model fine-tuned with differential privacy may still inadvertently reveal sensitive information learned during its initial training phase. This highlights the need for a more nuanced understanding of privacy in the context of LLMs, where the interplay between public and private data can complicate the assurances provided by differential privacy.
Key Takeaways
The landscape of machine learning security is evolving, with persistent threats like model stealing and data extraction.
Practical applications of security research are increasingly focused on real-world scenarios rather than hypothetical threats.
The balance between innovation in AI and the need for robust security measures is crucial for protecting sensitive data.
Actionable Insights
Organizations should conduct regular security audits of their machine learning models to identify potential vulnerabilities.
Implementing differential privacy techniques can help mitigate risks associated with data extraction and model stealing.
Security teams should stay informed about the latest research in adversarial machine learning to adapt their defenses proactively.
Why it’s Important
The discussion underscores the critical importance of integrating security considerations into the development and deployment of machine learning models. As AI technologies become more pervasive, the potential for exploitation increases, making it essential for organizations to prioritize security to protect sensitive data and maintain user trust.
What it Means for Thought Leaders
For thought leaders in the AI and machine learning space, the insights shared in the podcast highlight the necessity of fostering a culture of security awareness. They must advocate for the implementation of robust security frameworks and encourage collaboration between researchers and practitioners to address emerging threats effectively.
Mind Map
Key Quote
"Everything has changed because it's no longer a field that is focused on problems that may exist in some hypothetical scenario; it's now a question of attacks that someone actually would want to implement."
Future Trends & Predictions
As the field of machine learning continues to advance, we can expect an increase in the sophistication of attacks targeting AI models. The integration of security measures, such as differential privacy and robust model architectures, will become standard practice. Additionally, as organizations recognize the value of their data, the demand for security-focused research will likely grow, leading to more collaborative efforts between academia and industry to develop effective defenses against emerging threats.
Check out the podcast here:
Latest in AI
1. Microsoft has open-sourced its Phi-4 small language model on Hugging Face, releasing a powerful 14-billion-parameter AI tool under the permissive MIT license that enables both commercial and academic use. The model, which has demonstrated impressive performance in logical reasoning and mathematical tasks, outperforms larger models like Google's Gemini Pro in specific domains and was trained on a meticulously curated dataset of 9.8 trillion tokens. By making Phi-4 freely available, Microsoft aims to democratize AI development, foster community collaboration, and position itself as a key player in the open-source AI ecosystem.
2. Google is expanding NotebookLM's AI-powered audio generation capabilities to its Discover feed, allowing users to generate podcast-style audio summaries of articles and content directly within the platform. The feature, which leverages the Audio Overview technology first introduced in September 2024, will enable users to transform written content into conversational audio discussions with two AI hosts, complete with the ability to customize the tone and focus of the generated podcast.
3. Naver Corporation's 1784 headquarters in Bundang-gu, South Korea, has transformed the traditional office environment by deploying approximately 120 "Rookie" delivery robots that autonomously navigate the 36-story building, delivering everything from coffee to documents to employees. These AI-powered robots, which are "brainless" in the sense that they rely on a cloud-based intelligence system called ARC, use advanced technologies like 5G, digital twin mapping, and facial recognition to efficiently serve their human colleagues, even utilizing a dedicated "Roboport" - the world's first robot-only elevator system.
Useful AI Tools
1. Your Interviewer - Generate authentic content in seconds
2. Agents Base - Grow brands autonomously with marketing agents
3. TestSprite - AI agent that automates the software testing processes
Startup World
1. TikTok faces an imminent January 19th ban unless ByteDance divests its U.S. operations, with the Supreme Court hearings suggesting a high likelihood of the ban taking effect and potentially forcing the platform to cease operations in the United States. The potential ban would dramatically impact the 170 million U.S. users, including nearly 60% of adults under 30 and 63% of teenagers who rely on the platform, while also creating significant disruption for content creators who have built their careers and income streams on TikTok. While existing users can technically keep their app installed, they will be unable to receive critical updates, potentially exposing the app to security vulnerabilities and gradually degrading its functionality.
2. Vultr, a West Palm Beach-based cloud infrastructure startup founded in 2014, has raised $333 million in its first-ever external financing round, achieving a $3.5 billion valuation led by AMD Ventures and LuminArx Capital Management. The investment will enable Vultr to expand its global cloud infrastructure, particularly focusing on AI workloads, with the company operating 32 cloud data center regions across six continents and offering scalable, high-performance computing solutions.
3. The AI boom is creating a stark divide in the startup fundraising landscape, with AI companies securing high valuations while non-AI startups struggle to raise capital. Carta's data reveals a significant valuation disparity, with top Series B AI deals reaching nearly $1 billion pre-money valuation, while the bottom 10% of deals are valued at only $40 million. For non-AI startups, the fundraising environment remains challenging, with only 9% of Series A companies securing Series B funding within two years, down from 25% previously.
Analogy
Carlini’s insights on model stealing are like modern lock-picking in a digital age. Early locks (simple classifiers) were vulnerable to rudimentary tools, but today’s intricate safes (LLMs) demand more sophisticated techniques. Attackers no longer need the blueprint; just probing the lock (querying APIs) reveals its mechanisms. As organizations fortify their locks with better defenses, like limiting access to probability distributions, the game evolves. Yet, as with any security, the challenge isn’t just building better locks but staying one step ahead of those testing their vulnerabilities. Carlini’s work underscores the race between innovation in locks and the art of unlocking.
Thanks for reading, have a lovely day!
Jiten-One CerebralAll summaries are based on publicly available content from podcasts. One Cerebral provides complementary insights and encourages readers to support the original creators by engaging directly with their work; by listening, liking, commenting or subscribing.
Reply